Can Claude Scale a Service?
JR Tipton·
Progressively adding load to a service Claude manages
Previously, I had Claude operate a distributed key-value service that it did not have the source code for.
Here, I ran a similar process but made two changes to its environment:
- Claude has access to the service's source code.
- Claude can re-deploy the service.
The environment evolves differently. Instead of injecting chaos (like taking down a database shard), the environment's trials evolve the workload. The workload hits different limitations of the service's implementation Claude is encouraged to adapt the service to the changing workload.
chat-db-app
Chat-DB-App is a multi-user chat service with conversations, message history, full-text search, real-time notifications, and streaming AI responses. It's a sort of bread-and-butter service that fronts a Postgres database, pretending to be a chatbot's conversation index.
Its implementation is correct, in a sense, but naive: it hides around 20 common anti-patterns: missing database indexes, connection pool mismanagement, N+1 queries, race conditions, and more. The app works fine under light traffic.
When the eval harness turns up the heat with more users, faster requests, heavier workloads, etc., then it starts to break down. The operator's job is to notice when things start breaking, dig into the code to find the root cause, and ship a fix, just like a real on-call engineer would.
The app starts with the implementation here.
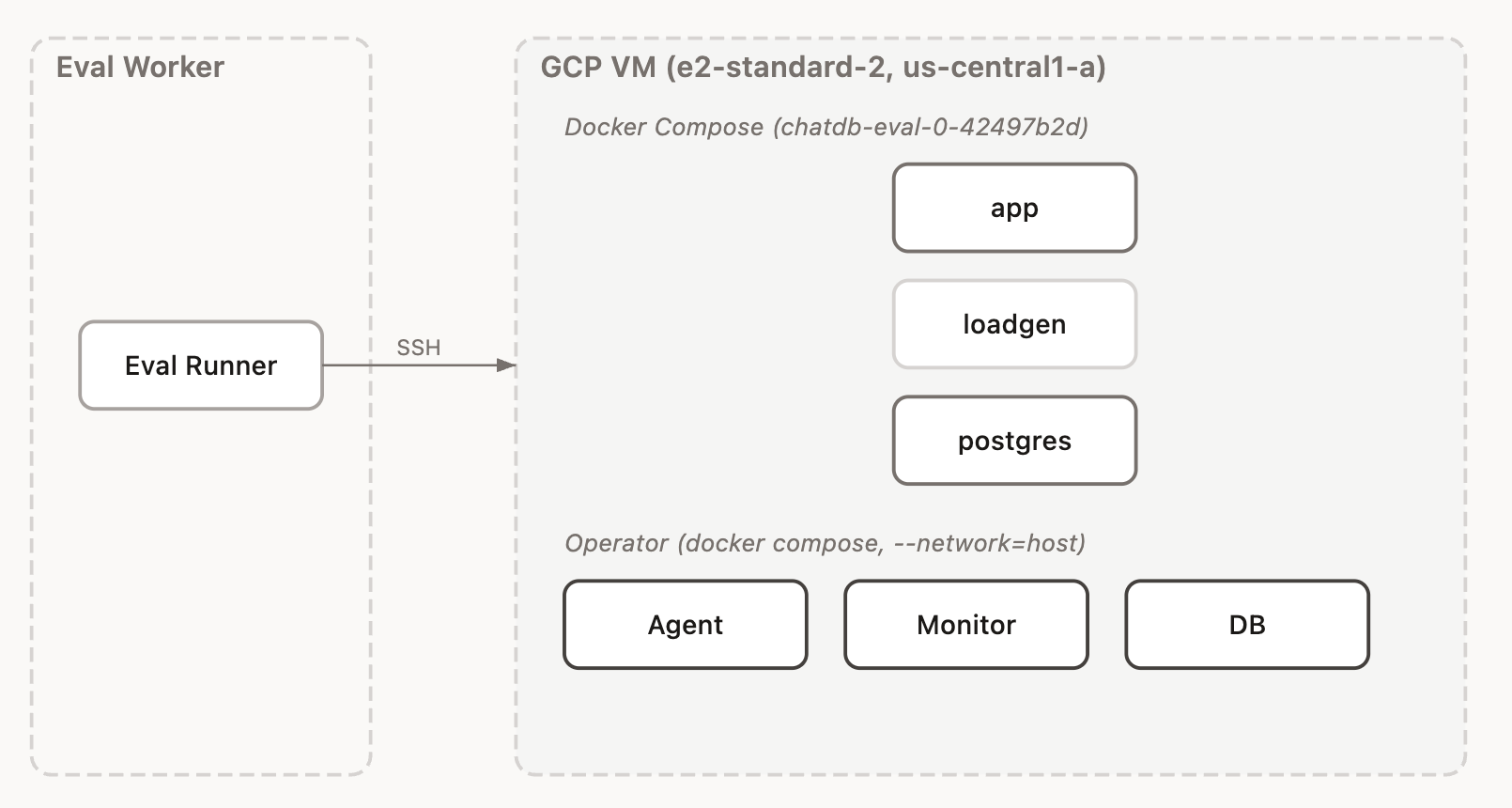
Ratcheting the load
The load generator starts gentle, a handful of simulated users chatting at a relaxed pace, and then the sequential campaign progressively turns up the heat across 18 trials.
It begins with basic database pressure: more users, faster requests, and heavier read patterns that expose missing indexes and connection pool limits. From there it escalates into trickier territory like burst writes that trigger race conditions, streaming requests that hold transactions open too long, and searches that force expensive full-table scans.
The second half shifts focus to the (admittedly artificial) notification system, where the real pain compounds. Broadcasts fan out to thousands of users, long-polling eats up all available connections, and unread counts trigger expensive queries on every single request. Because the campaign runs continuously without resetting between stages, each new load profile stacks on top of the damage left by previous ones.
The operator is given its prior state, again and again, to continue its work.

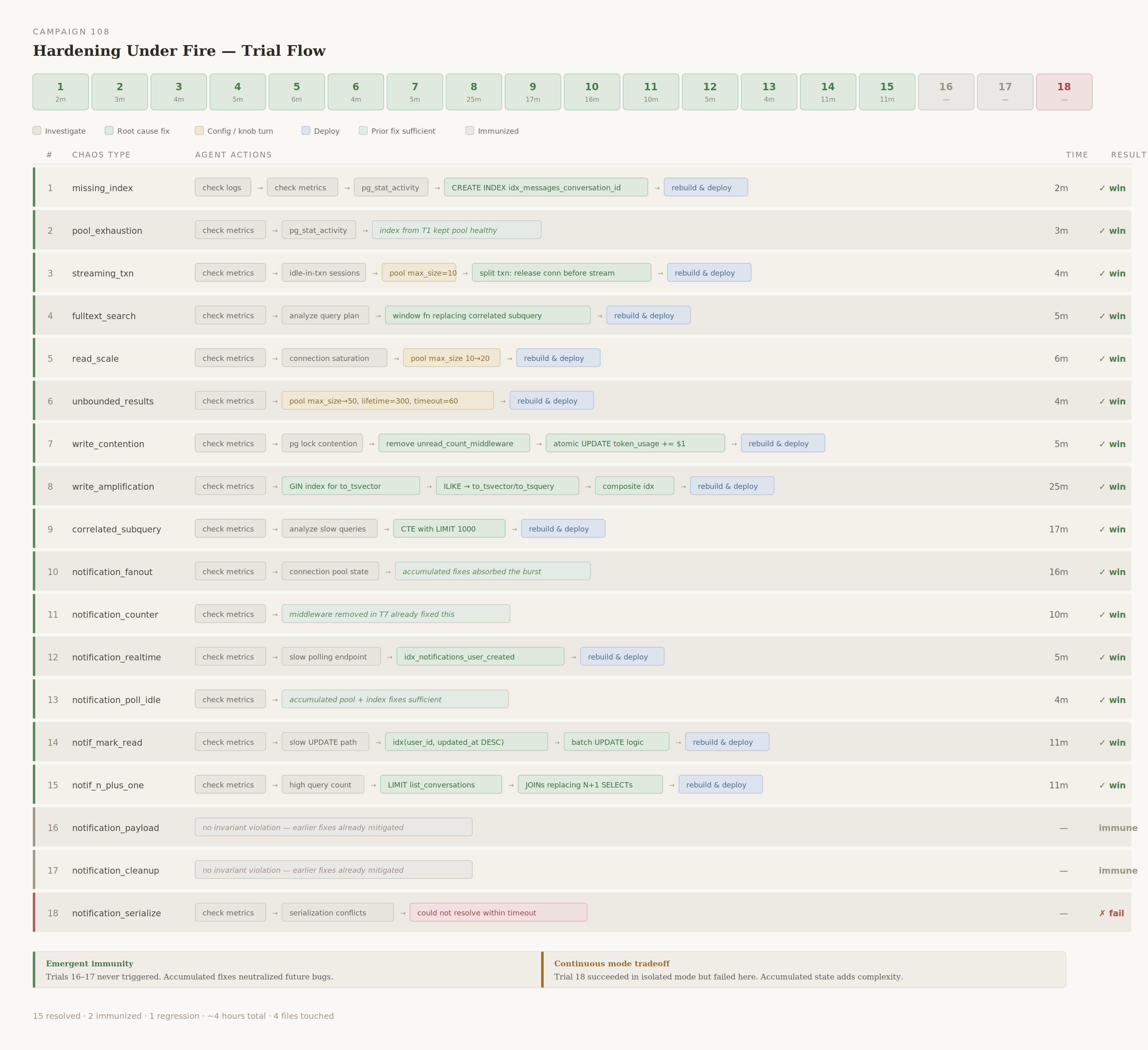
Results
The campaign is a series of trials run back to back, without state changes. The operator is reset but the app is not.
The campaign summary, and links to details of each trial, are compiled in a campaign report. The final app source code artifact -- a result of the agent's changes -- is visible here.
Key results (83% win rate, 15/18):
- The agent diagnosed and fixed 15 distinct code-level performance bugs in sequence, building a progressively more sophisticated service over ~4 hours.
- Earlier fixes created what you might think of as emergent immunity: by trial 16, the agent had added indexes, fixed N+1 queries, batch-ified updates, capped result sets, and removed expensive middleware. Two of the three trial "failures" (
notification_payloadandnotification_cleanup) never even triggered an invariant violation. The fixes from earlier trials had already mitigated the symptoms.
The behavioral timelines show a consistent pattern: the agent investigates (logs, metrics, connection state), identifies the problematic code path, makes a targeted fix (often a single-file edit), deploys, and verifies. The fixes are real: it adds B-tree indexes, rewrites queries, converts synchronous loops to batch operations, and fixes connection pool sizing.
Summary
The harness throws load at Chat-Db-App that reveal limitations in the naive service's implementation. These are limitations, or perhaps bugs, that work fine in development and only surface under production-scale load. They're the kind of thing an engineer or a team might find after an outage, and then turnaround and fix.
Appendix: Scaling issues at a glance
Query performance bugs:
- missing_index — The app queries messages by conversation_id with no index, forcing PostgreSQL into sequential scans on every lookup. With thousands of messages, every API call crawls.
- correlated_subquery — A running token total is computed per-message using a correlated subquery, turning what should be O(N) into O(N^2). At 10K+ messages, a single page load can take minutes.
- fulltext_search — Search uses ILIKE '%term%' which can't use indexes. Every search request scans the entire messages table.
Connection/resource exhaustion:
- pool_exhaustion — The connection pool has no upper bound. Under load, the app opens connections until it hits PostgreSQL's max_connections limit, then every new request fails.
- streaming_txn — Streaming chat responses hold a database transaction open for the entire generation time. A handful of concurrent streams can lock up the entire connection pool with idle-in-transaction connections.
Write path bugs:
- counter_race — Token counting uses read-modify-write instead of atomic increment. Under concurrent writes, counts silently lose updates.
- write_contention — Every message insert also UPDATEs the conversation and user rows. High concurrency creates a lock convoy where transactions queue up waiting for the same rows.
Notification system bugs:
- notification_fanout — Broadcasting a notification inserts one row per user in a synchronous loop. With 1000+ users, a single broadcast blocks for 30+ seconds.
- notification_n_plus_one — Listing notifications fetches each conversation title with a separate SELECT. 1000 notifications = 1001 queries.
Appendix: How the code evolved over the trials
| Trial | Chaos Type | What the Agent Did | Result |
|---|---|---|---|
| 1 | missing_index | Added CREATE INDEX idx_messages_conversation_id ON messages(conversation_id). Queries were doing sequential scans on every message lookup. One line, immediate recovery. |
✓ 2m |
| 2 | pool_exhaustion | No new code change needed. The index from trial 1 reduced query time enough to keep the pool healthy. | ✓ 3m |
| 3 | streaming_txn | Two fixes. Capped the connection pool at max_size=10. Restructured streaming code to split one long transaction into two short ones: acquire a connection to insert the user message, release it, stream the response without holding a connection, then acquire again to insert the assistant message. The original code held a DB connection idle for the entire streaming duration. |
✓ 4m |
| 4 | fulltext_search | Rewrote the correlated subquery (SELECT SUM(token_count) ... WHERE conversation_id = m.conversation_id AND created_at <= m.created_at) into a window function: SUM(token_count) OVER (ORDER BY created_at ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW). Turned O(N²) into O(N). The agent spotted this proactively while investigating the fulltext issue. |
✓ 5m |
| 5 | read_scale | Increased pool size from max_size=10 to max_size=20 to handle 60+ concurrent readers. |
✓ 6m |
| 6 | unbounded_results | Increased pool to max_size=50, added max_inactive_connection_lifetime=300 and command_timeout=60. Defensive pool tuning. |
✓ 4m |
| 7 | write_contention | Removed unread_count_middleware, which ran COUNT(*) on unread notifications on every API request. Fixed the token counter race condition: replaced read-modify-write (SELECT token_usage; UPDATE SET token_usage = old + new) with atomic UPDATE SET token_usage = token_usage + $1. |
✓ 5m |
| 8 | write_amplification | Added a GIN index for full-text search: CREATE INDEX ... USING GIN (to_tsvector('english', content)). Rewrote search_messages to use to_tsvector/to_tsquery instead of ILIKE '%term%'. Added composite index on messages(conversation_id, created_at). |
✓ 25m |
| 9 | correlated_subquery | Rewrote get_messages to use a CTE with LIMIT 1000, capping the result set for large conversations. Combined with the window function from trial 4, this bounded both the number of rows and the computation per row. |
✓ 17m |
| 10 | notification_fanout | No new structural fix. The fanout was synchronous INSERT-per-user, but by this point the pool was large enough and earlier optimizations (removed unread-count middleware, indexed lookups) reduced baseline load enough to absorb the burst. | ✓ 16m |
| 11 | notification_counter | No new fix needed. The unread-count middleware removed in trial 7 already addressed this. | ✓ 10m |
| 12 | notification_realtime | Added idx_notifications_user_created index on notifications(user_id, created_at) to speed up the polling endpoint. |
✓ 5m |
| 13 | notification_poll_idle | No new fix needed. Accumulated pool and index fixes handled this. | ✓ 4m |
| 14 | notification_mark_read | Added index on conversations(user_id, updated_at DESC) plus batch UPDATE logic to replace per-row updates. |
✓ 11m |
| 15 | notification_n_plus_one | Added LIMIT to list_conversations, rewrote notification listing to use JOINs instead of N+1 SELECTs. |
✓ 11m |
| 16 | notification_payload | No invariant violation fired. Accumulated fixes from trials 1-15 had already reduced latency enough that this chaos type couldn't trigger symptoms. | immune |
| 17 | notification_cleanup | No invariant violation fired. Same as trial 16: the system was already resilient. | immune |
| 18 | notification_serialize | Ticket created but the agent couldn't resolve the SERIALIZABLE conflict within the timeout. This chaos type succeeded in isolated mode (campaign 107) but failed under accumulated state from continuous mode. |
✗ fail |
The cumulative diff by the end touched 4 files:
models.py: 6 new indexes, window function replacing correlated subquery, CTE withLIMIT, atomic token counter, batch updates, JOINs replacing N+1pool.py:max_size, connection lifetime, command timeoutstreaming.py: split single long transaction into two short onesmain.py: removed per-request unread-count middleware