Claude Operator
JR Tipton·
Can Claude Operate a Distributed System?
I ran a few experiments where Claude acts as a backend service operator.
This came about from a basic question: if we're able to build services faster than ever, who is going to operate those services? The question I wanted to answer is whether Claude could manage to operate a service.
Here, the term 'operator' means something like an SRE intern. Or, alternatively, some automation that isn't a set of rules.
Putting Claude in the operator seat
I put Claude inside of a node that is allowed to make changes on another subject system. There's a monitor service that observes the behavior of the subject system. When it sees violations of invariants (e.g. all API latencies should be under 100ms), the monitor service files a "ticket" with its observation into a database that Claude can pull from.
Then the agent node uses the Claude Agent SDK in a loop to diagnose the problem and to fix it.
The overall system (source) is called operator. It has just a few parts:
- A
subjectis the service we want to operate. - The
monitordaemon watches metrics about thesubject. Thesubjectdefines and implements this. - The
agentservice acts on observations frommonitor, and does what it can to get thesubjectinto a healthy state. - There's a small protocol for implementing new
subjects.
operator is simple. The agent logic is <400 lines of code (source), and all of operator is <3000 lines (excluding tests).
Putting it through the paces
I put a basic harness around operator and subject that sets the services up in GCP. It then runs a campaign of individual tests or trials. In each trial, we either do nothing (base case) or we inject some chaos.
The harness, called eval, captures information for later analysis:
- The tickets that the monitor service files for the agent to complete go into the final data set.
- The harness captures all of the commands the agent ran.
- If the
subjectexposes its source code to theagent, the harness captures any changes in the form of a git repo. - If the
subjecthas a database, harness captures schema, indexes, settings, etc. from the before and after states.
A distributed key-value service
I started with a fake rate limiter service that uses Redis (source). It performed pretty well on this, even figuring out that someone (me) was up to no good (injecting chaos). Clearly we needed something more serious.
TiKV is an open source distributed key value store. This gave us an opportunity to try more interesting failures to inject:
node_killsendsSIGKILLto a TiKV containerlatencyusestcto inject network latencyasymmetric_partitionblocks traffic to one peerpd_leader_killkills a random control plane nodeleader_concentrationputs all region leaders on one store
The agent has shell access to the Docker host running the cluster, but no ability to edit TiKV's source code. Everything it does is through CLI tools: docker commands, curl to PD's HTTP API, iptables, tc traffic control, and process signals. This is how we might envision a first pass at a junior SRE's role.
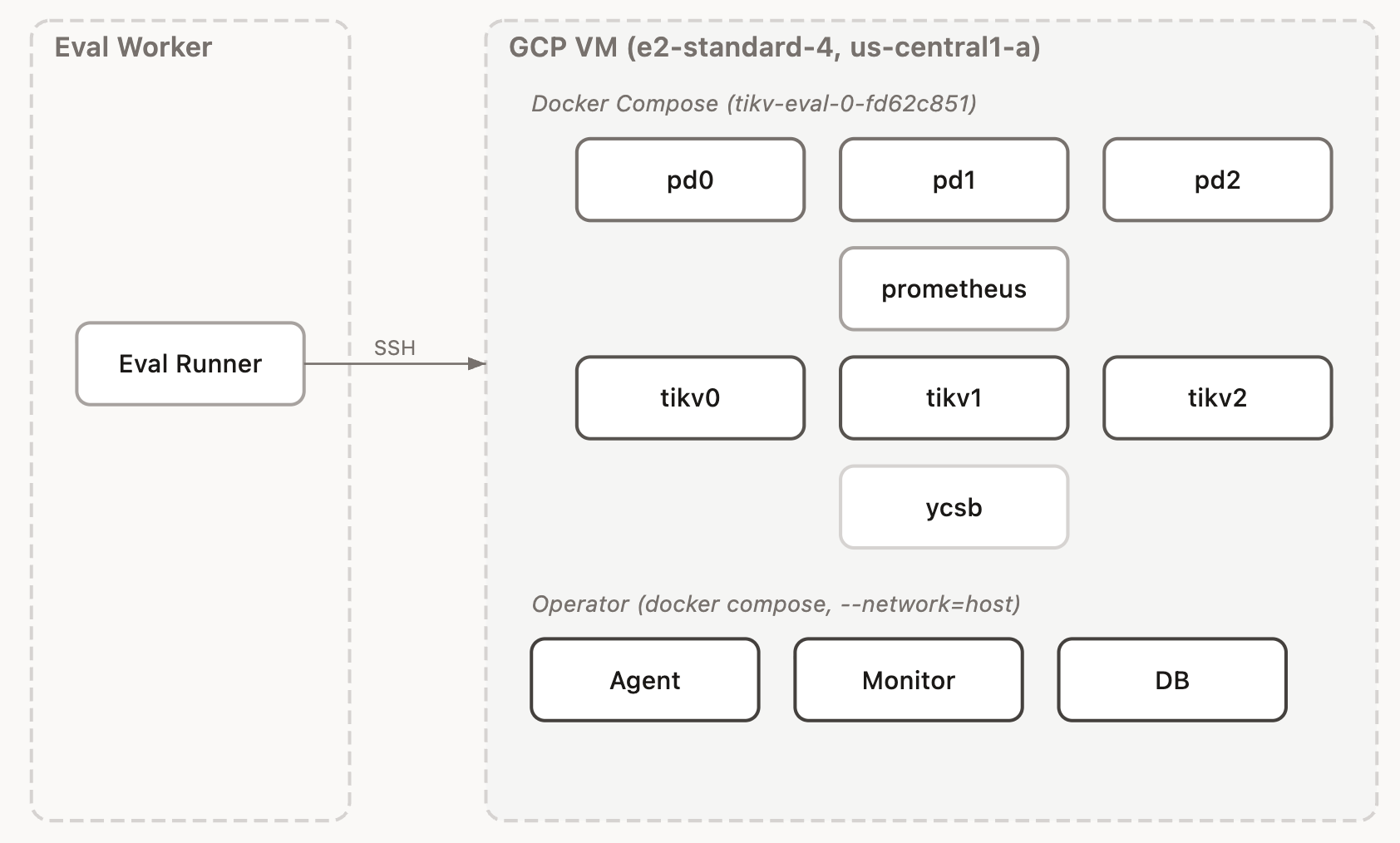
Results
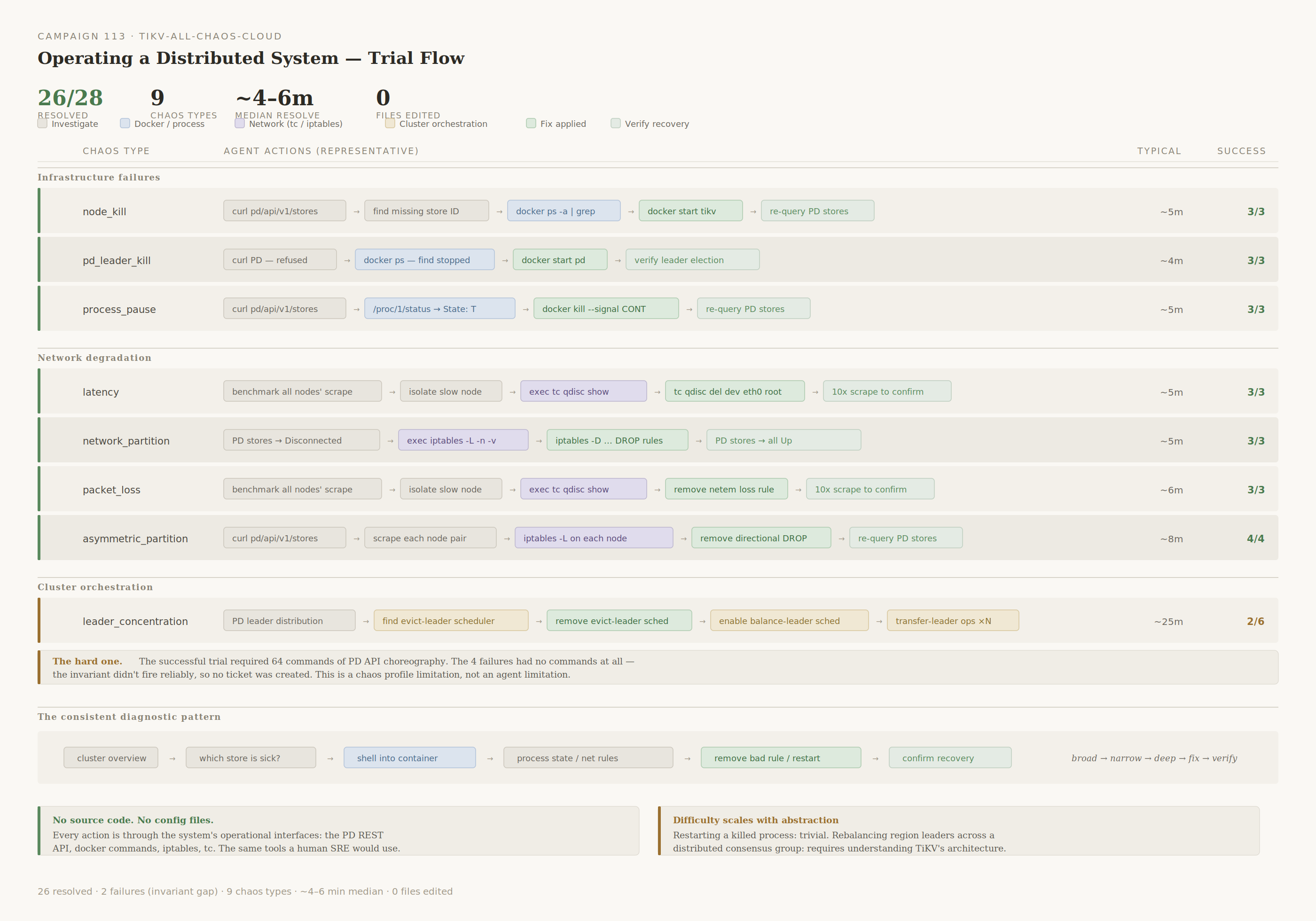
I ran a campaign of nine different kinds of chaos (different sorts of failures injected into the system). Each of these ran three times. In all cases, the entire environment is reset: each trial is evaluated as an independent event.
In 28 trials across 9 chaos types, a very basic Claude setup with minimal prompting shows a 93% win rate (26/28). The campaign, and all trial details, are on GitHub.
The chaos types fall into three categories: infrastructure failures, network degradation, and cluster orchestration.
The diagnostic pattern is consistent across chaos types: start broad (cluster overview via PD API), narrow down (which store is unhealthy?), go deep (shell into the container, check process state, inspect network rules), fix (remove the bad rule, restart the process, rebalance leaders), verify (re-query PD, confirm recovery).
For example, in a packet_loss trial, the agent ran 26 commands. It started by querying PD for store status, benchmarked scrape times across all three TiKV nodes to isolate the slow one, shelled in to inspect tc qdisc, found the netem loss rule, removed it, then ran 10 consecutive scrapes to confirm latency was back to normal.
In a leader_concentration trial, the agent queried PD's scheduler config, found and removed the evict-leader scheduler, re-enabled balance-leader scheduling, then manually issued transfer-leader operators for individual regions to redistribute leaders across stores. This is the kind of PD API choreography that requires understanding how TiKV's placement driver works.
Appendix: Results in Detail
| Chaos Type | What Happens | What the Agent Does |
|---|---|---|
| node_kill | A TiKV container is killed with SIGKILL. | Queries pd/api/v1/stores to discover the missing store, matches it to a container name via docker ps, and restarts it. |
| pd_leader_kill | The PD control plane leader is killed. | Notices PD is unreachable, finds the stopped container, starts it, and verifies the cluster re-elects a leader. |
| process_pause | A TiKV process is frozen with SIGSTOP. The container is still running but the process isn't responding. | Checks process state via /proc/1/status inside the container, sees State: T (stopped), and sends SIGCONT to resume it. |
| latency | Traffic control rules add 50–150ms latency to one TiKV node. | Benchmarks response times across all nodes to isolate the slow one, shells into the container, inspects tc qdisc show, and removes the netem rule. |
| network_partition | iptables rules block a TiKV node from communicating with peers and PD. | Sees the node is "Disconnected" in PD's store list, inspects iptables inside the container, and removes the DROP rules. |
| packet_loss | tc netem drops a percentage of packets. |
Measures scrape times across nodes, finds the outlier, inspects tc rules, removes them. |
| asymmetric_partition | One-directional traffic block to a single peer. | Has to figure out which direction is blocked. Scrapes each node pair, inspects iptables on each, removes the directional DROP rule. One trial took 25 minutes of deep investigation. |
| leader_concentration | All region leaders are forced onto one store via PD's evict-leader-scheduler. | Queries PD for leader distribution, identifies the evict-leader scheduler, removes it, re-enables the balance-leader scheduler, and manually transfers leaders using transfer-leader operators. One successful trial required 64 commands. The 4 failures had no commands at all — the invariant didn't fire reliably enough to create a ticket. This is a chaos profile limitation, not an agent limitation. |
Further reading
In claude-service-scaler, I explore what happens when Claude has access to a service's source code and the service's workload changes and scales over time.